



 后端及数据库
后端及数据库
 Flask
Flask Tornado
Tornado Django
Django Redis
Redis liunx
liunx 前端
前端
 JavaScript
JavaScript Vue框架
Vue框架 机器学习
机器学习
 多元线性模型
多元线性模型.png) 决策树
决策树 无监督学习
无监督学习 概率图
概率图 支持向量机
支持向量机 论文阅读
论文阅读
 其他
其他 金融学
金融学
 金融经济学25讲
金融经济学25讲 期货、期权及其他衍生品
期货、期权及其他衍生品 宏观经济学25讲
宏观经济学25讲 资产定价
资产定价 数学
数学
 随机过程
随机过程.png) 统计学
统计学 概率论
概率论 优化方法
优化方法 计量经济学
计量经济学
 中级计量
中级计量 stata
stata 深度学习
深度学习
 DNN
DNN CNN
CNN RNN
RNN NLP
NLP GAN
GAN GNN
GNN KG
KG 数据结构
数据结构
.png) 常用结构
常用结构 图论
图论 树结构
树结构 python
python
 并发编程
并发编程 爬虫
爬虫 量化Quant
量化Quant.png) 其他
其他# 金融科技
-

Machine-learning the skill of mutual fund managers
我们利用机器学习方法证明,基金特征能够一贯地区分高绩效与低绩效的共同基金,无论是在费用之前还是之后。这种超额表现持续超过三年。 基金动量和资金流是预测未来风险调整后基金表现最重要的因素,而基金持有的股票特征则不具备预测能力。 在高情绪期间之后,预测性多空组合的回报更高。我们使用神经网络进行的估计使我们能够揭示情绪与资金流及基金动量之间的新颖且显著的交互效应。
 金融科技
金融科技
-
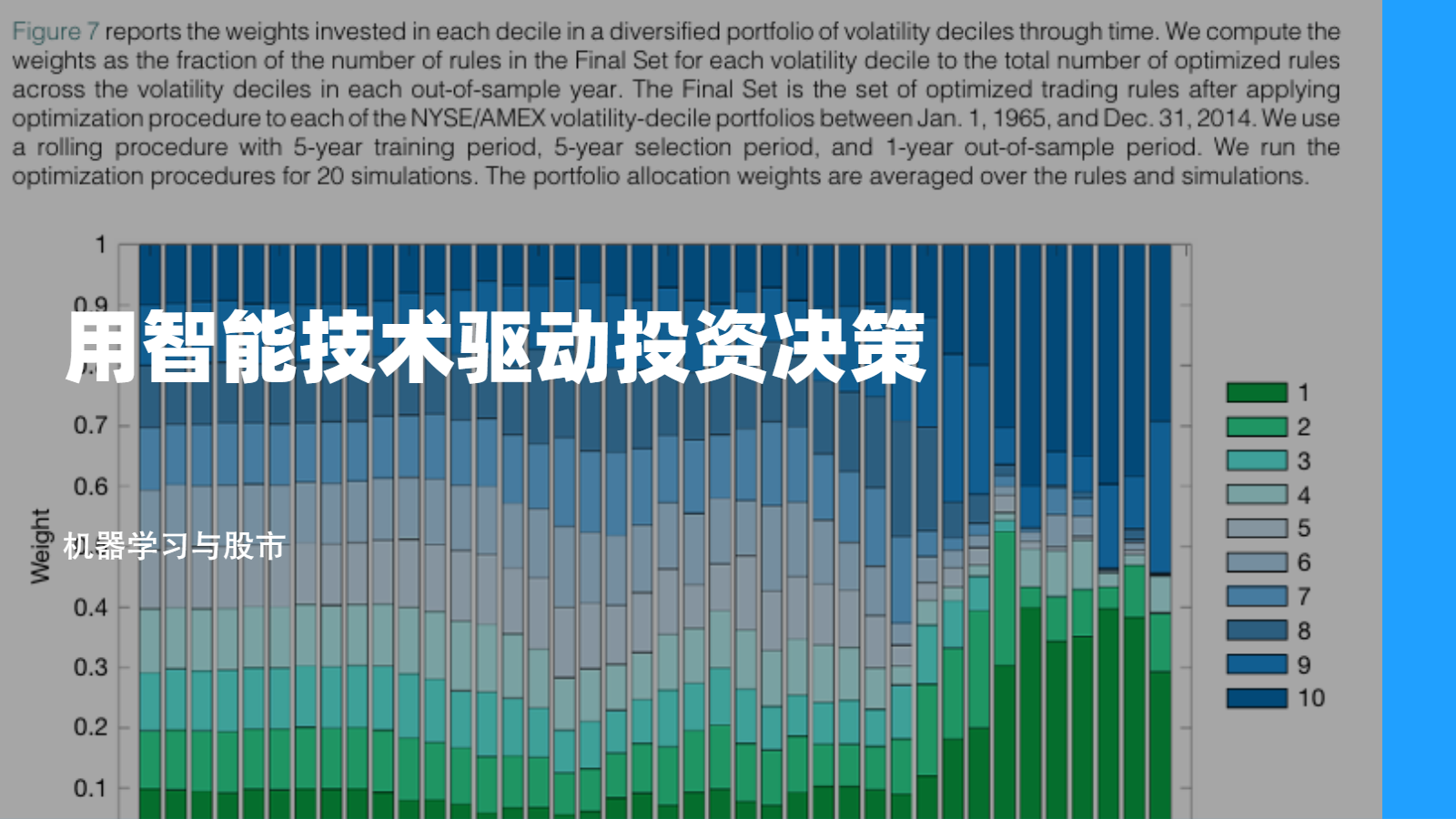
machine learning and the stock market 论文阅读
在本文中,我们利用机器学习技术来寻找盈利的交易规则。我们采用了一套多样化的机器学习方法,除了标准的损失最小化算法(例如支持向量机、决策树、随机森林和集成学习)之外,还包括进化遗传算法。此外,我们的实验伴随着严格的数据窥探和交易成本控制。结果表明,投资者本可以事先找到盈利的技术交易规则,但这种样本外的盈利能力随着时间逐渐减少。而且,我们的发现提倡使用进化遗传算法而非基于损失最小化的机器学习算法(如随机森林和决策树)。
金融科技
-

Machine Learning and Fund Characteristics Help to Select Mutual Funds with Positive Alpha 论文详解
基于机器学习的方法,仅利用基金特征选择公募基金组合,获得了显著的样本外α值。些方法揭示了基金特征与未来业绩之间关系中的相互作用。例如,对于更加积极主动的基金而言,过去的表现是预测未来表现特别有力的指标。机器学习识别出那些技能没有被规模不经济充分抵消的经理,这与阻止投资者识别表现优异的基金的信息摩擦是一致的。本文的发现表明,投资者可以从积极管理中受益,但前提是他们能够获得复杂的预测方法。
金融科技
-
.jpeg)
Expectation disarray: Analysts’ growth forecast anomaly in China 论文阅读
在本研究中,我们考察了分析师收益增长预测对中国资产定价的影响。我们的发现与之前在美国市场进行的研究有所不同。具体来说,我们发现分析师的增长预测在中国对股票回报具有正面的预测能力。我们的结果表明,在中国,投资者的预期并没有与分析师的预测保持一致。因此,分析师预测中的偏差似乎并没有扭曲价格。这并不是因为投资者有效地过滤了这些偏差,而是因为这些预测从一开始就基本上被忽视了
金融科技
-

FinLex: An effective use of word embeddings for financial lexicon generation 论文阅读
本文介绍了一种名为FinLex的新方法,该方法在处理法律和金融文本的语言模型(LM)词汇表构建方面展示出了与现有最佳技术相媲美的性能。FinLex主要解决了传统上依赖专家手动创建词汇表所带来的主观性和非标准化问题。随着概念随时间和语境的变化,人工创建的方法难以保持词汇表的更新与一致。FinLex的创新之处在于使用算法自动构建词汇表,减少了人为因素的影响,提高了过程的可重复性和透明度。此外,这种方法不仅没有排除领域专家的参与,反而为他们提供了一个优化的基础。
金融科技
-

USING MD&A TO IMPROVE EARNINGS FORECASTS 论文阅读
在本文中,我们开发了将文本与财务变量相结合的技术,以生成明确的公司层面预测。我们发现,增强文本的模型比仅使用定量财务变量的模型更准确,提供了关于MD&A部分预测价值的证据。具有本期业绩变化较小、未来业绩变化较大、未来业绩变化为负、应计项目较高、市值更大、Z评分较低、审计质量更高、MD&A文本较短且更易读、以及激励性薪酬较高的公司的MD&A更具信息量。MD&A在监管改革之后的时期内更具信息量,但在最近的金融危机期间则信息量较少。最后,我们表明,在小型企业和分析师关注度较低的企业中,分析师相对于增强文本的统计模型而言失去了其预测优势。
金融科技
-

Predicting Future Earnings Changes Using Machine Learning and Detailed Financial Data 论文阅读
使用机器学习方法和高维详细财务数据来预测一年后的收益变化方向。我们的模型显示出显著的样本外预测能力:受试者操作特征曲线(ROC)下的面积(AUC)在67.52%到68.66%之间,这明显高于随机猜测的50%。根据我们模型预测形成的对冲组合的年度规模调整后收益在5.02%到9.74%之间。我们的模型优于两种传统模型,这两种传统模型使用逻辑回归和少量的会计变量,并且也优于专业分析师的预测。分析表明,相对于传统模型的优越性既来自于回归所忽略的非线性预测变量相互作用,也来自于机器学习利用了更详细的财务数据。
金融科技
-

When is a Liability not a Liability? Textual Analysis, Dictionaries, and 10-Ks(2011) 论文阅读
先前的研究使用负面词汇的数量来衡量文本的基调。我们表明,为其他学科开发的词汇表会误分类金融文本中常见的词汇。在1994年至2008年间大量10-K报告的样本中,几乎四分之三被广泛使用的哈佛词典标记为负面的词汇,在金融语境中通常并不被认为是负面的。我们开发了一个替代的负面词汇表,以及另外五个词汇表,这些词汇表更好地反映了金融文本中的基调。我们将这些词汇表关联到10-K申报回报、交易量、回报波动性、欺诈、重大缺陷以及意外收益上。
金融科技
-

From Man vs Machine to Man + Machine: The Art and AI of Stock Analyses 论文阅读
人工智能分析师,在股票收益预测方面超越了大多数分析师。涉及无形资产和财务困境时,“人机对抗”中人类仍然胜出。当信息透明但量大时,人工智能则更胜一筹。在“人机协作”模式下,人类提供了显著的增量价值,并且大幅减少了极端错误的发生。如果分析师的雇主构建了人工智能能力,在“另类数据”变得可用之后,分析师能够赶上机器的表现。
金融科技
-

Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 论文阅读
我们探讨了生成连锁思维——一系列中间推理步骤——如何显著提高大型语言模型执行复杂推理的能力。特别地,我们展示了通过一种简单的方法,称为连锁思维提示,在提供一些连锁思维示例作为提示的情况下,大型语言模型自然地表现出这种推理能力。在三个大型语言模型上的实验表明,连锁思维提示在一系列算术、常识和符号推理任务上提高了性能。这种实证收益是显著的。例如,仅使用八个连锁思维示例提示PaLM 540B,就在GSM8K数学题解基准上达到了最先进的准确性,甚至超过了微调过的带验证器的GPT-3。
金融科技