
加餐部分 -- 潘登同学的图论笔记
加餐第一题: 骑士周游问题DFS实现
- 题目: > 考虑国际象棋棋盘上某个位置的一只马,它是否可能只走63步,正好走过除起点外的其他63个位置各一次?如果有一种这样的走法,则称所走的这条路线为一条马的周游路线。试设计一个算法找出这样一条马的周游路线。
此题实际上是一个汉密尔顿通路问题,可以描述为:
在一个8×8的方格棋盘中,按照国际象棋中马的行走规则从棋盘上的某一方格出发,开始在棋盘上周游,如果能不重复地走遍棋盘上的每一个方格, 这样的一条周游路线在数学上被称为国际象棋盘上马的哈密尔顿链。请你设计一个程序,从键盘输入一个起始方格的坐标,由计算机自动寻找并打印 出国际象棋盘上马的哈密尔顿链。
算法很经典不过多解释了,但在实现的过程中用了一个启发式的算法Warnsdorff算法,目的只是加快DFS过程
话不多说,上代码!!!
#%%骑士周游问题
from Vertex import Vertex # 导入Vertex
from Graph import Graph # 导入之前实现的Graph
class New_Vertex(Vertex): # 某一个具体问题的数据结构需要继承原有数据结构
def __init__(self, key):
super().__init__(key)
self.color = 'white' # 新增类属性(用于记录节点是否被走过)
# 新增类方法, 设置节点颜色
def setColor(self, color):
self.color = color
# 新增类方法, 查看节点颜色
def getColor(self):
return self.color
class New_Graph(Graph): # 继承Graph对象
def __init__(self):
super().__init__()
# 重载方法 因为原先Graph中新增节点用的是Vertex节点,但现在是用New_Vertex
def addVertex(self, key): # 增加节点
'''
input: Vertex key (str)
return: Vertex object
'''
self.numVertices = self.numVertices + 1
newVertex = New_Vertex(key) # 创建新节点
self.vertList[key] = newVertex
return newVertex
class Solution(object):
# 构造图
def knightGraph(self, bdSize):
ktGraph = New_Graph()
for row in range(bdSize):
for col in range(bdSize):
index = bdSize * row + col # 当前节点索引(key)
newPositions = self.genLegalMoves(row, col, bdSize) # 下一个节点的集合
for i in newPositions:
index_next = bdSize*i[0]+i[1]
ktGraph.addEdge(index, index_next, 1)
return ktGraph
# 判断马的走法是否合法
def genLegalMoves(self, x, y, bdSize):
newMoves = []
# 马的走棋规则
moveOffsets = [(-1, -2), (-1, 2), (-2, -1), (-2, 1),
(1, -2), (1, 2), (2, -1), (2, 1)]
for i in moveOffsets:
newX = x + i[0]
newY = y + i[1]
if self.legalCoord(newX, bdSize) and self.legalCoord(newY, bdSize):
newMoves.append((newX, newY))
return newMoves
def legalCoord(self, x, bdSize): # 查看落点是否越界
if x >= 0 and x < bdSize:
return True
else:
return False
# 深度优先搜索
def DFS(self, g, start):
result = []
# 回溯
def trace(path, g, start): # path是探索的路径 g是图,start是起始的节点
start.setColor('gray') # 将正在探索的节点设置为灰色
path.append(start)
if len(path) == 64: # 64是总的目标(走完棋盘)
result.append(list(path))
return
else:
for i in list(start.getConnections()):
if i.getColor() == 'white':
trace(path, g, i)
path.pop()
i.setColor('white')
trace([], g, start)
return result
# 回溯改进Warnsdorff算法
# 将strat 的合法移动目标棋盘格排序为:具有最少合法移动目标的格子优先搜索
# def Warnsdorff(g, start):
# Warnsdorff算法
def Warnsdorff(self, path, g, start): # path是探索的路径 g是图,start是起始的节点
start.setColor('gray') # 将正在探索的节点设置为灰色
path.append(start)
temp_choice = list(self.orderByAvail(start))
for i in temp_choice:
if i.getColor() == 'white':
self.Warnsdorff(path, g, i)
if len(path) == 64: # 64是总的目标(走完棋盘)(这与完全遍历有区别)
return path # 完全遍历的判断语句就在函数前端,这个只要找到一个就行
path.pop()
i.setColor('white')
# 这个函数的目的是把要探索的节点按照走的先后次序进行排序(按照下下步选择少的排在前面)
# 相当于先验知识(启发式算法)
def orderByAvail(self, start):
reslist = []
for i in start.getConnections():
if i.getColor() == 'white':
c = 0
for j in i.getConnections():
if j.getColor() == 'white':
c += 1
reslist.append((c, i))
reslist.sort(key=lambda x: x[0])
return [y[1] for y in reslist]
# trace1([], g, start)
# return result
if __name__ == '__main__':
s = Solution()
g = s.knightGraph(8)
path = s.Warnsdorff([], g, g.getVertex(0))
for i in path:
print(i.getId(), end=' ')
加餐第二题: 词梯问题BFS实现
题目:
从一个单词演变到另一个单词,其中的过程可以经过多个中间单词。 要求是相邻两个单词之间差异只能是1个字母
从FOOL到SAGE的过程

注意的地方:
图结构的构建有点复杂,主要思想就是构建词梯桶,把两个相差一个字符的单词构建一条边
然后就是BFS的实现了
广度优先算法(先从距离为1开始搜索节点,搜索完所有距离为k才搜索距离为k+1)
(图的数据结构修改) 为了跟踪顶点的加入过程,并避免重复顶点,要为顶点增加三个属性 距离distance:从起始顶点到此顶点路径长度 前驱顶点predecessor:可反向追随到起点 颜色color:标识了此顶点是尚未发现(白色),已经发现(灰色),还是已经完成探索(黑色)
(新加队列数据结构) 还需用一个队列Queue来对已发现的顶点进行排列 决定下一个要探索的顶点(队首顶点)
BFS算法过程 从起始顶点s开始,作为刚发现的顶点,标注为灰色,距离为0,前驱为None, 加入队列,接下来是个循环迭代过程:
从队首取出一个顶点作为当前顶点;遍历当前顶点的邻接顶点,如果是尚未发现的白色顶点,则将其颜色改为灰色(已发现),距离增加1,前驱顶点为当前顶点,加入到队列中
遍历完成后,将当前顶点设置为黑色(已探索过),循环回到步骤1的队首取当前顶点
话不多说,上代码!!!
#%% 词梯问题BFS算法
from Vertex import Vertex # 导入Vertex
from Graph import Graph # 导入之前实现的Graph
import sys
class New_Vertex(Vertex): # 某一个具体问题的数据结构需要继承原有数据结构
def __init__(self, key):
super().__init__(key)
self.color = 'white' # 新增类属性(用于记录节点是否被走过)
self.dist = sys.maxsize # 新增类属性(用于记录strat到这个顶点的距离)初始化为无穷大
self.pred = None # 顶点的前驱 BFS需要
# 新增类方法, 设置节点颜色
def setColor(self, color):
self.color = color
# 新增类方法, 查看节点颜色
def getColor(self):
return self.color
# 新增类方法, 设置节点前驱
def setPred(self, p):
self.pred = p
# 新增类方法, 查看节点前驱
def getPred(self): # 这个前驱节点主要用于追溯,是记录离起始节点最短路径上
return self.pred # 该节点的前一个节点是谁
# 新增类方法, 设置节点距离
def setDistance(self, d):
self.dist = d
# 新增类方法, 查看节点距离
def getDistance(self):
return self.dist
class New_Graph(Graph): # 继承Graph对象
def __init__(self):
super().__init__()
# 重载方法 因为原先Graph中新增节点用的是Vertex节点,但现在是用New_Vertex
def addVertex(self, key): # 增加节点
'''
input: Vertex key (str)
return: Vertex object
'''
if key in self.vertList:
return
self.numVertices = self.numVertices + 1
newVertex = New_Vertex(key) # 创建新节点
self.vertList[key] = newVertex
return newVertex
# %词梯问题:采用字典建立桶(每个桶有三个字母是相同的 比如head,lead,read
# 那么每个词梯桶内部所有单词都组成一个无向且边为1的图
def buildGraph(wordfile):
d = {}
g = New_Graph()
wfile = open(wordfile, 'r')
# 创建桶,每个桶中只有一个字母是不同的
for line in wfile:
word = line[:-1]
for i in range(len(word)): # 每一个单词都可以属于4个桶
bucket = word[:i] + '_' + word[i+1:]
if bucket in d:
d[bucket].append(word)
else:
d[bucket] = [word]
# 在桶内部建立图
for bucket in d.keys():
for word1 in d[bucket]:
for word2 in d[bucket]:
if word1 != word2:
g.addEdge(word1, word2)
return g
# %广度优先算法(先从距离为1开始搜索节点,搜索完所有距离为k才搜索距离为k+1)
'''
为了跟踪顶点的加入过程,并避免重复顶点,要为顶点增加三个属性
距离distance:从起始顶点到此顶点路径长度
前驱顶点predecessor:可反向追随到起点
颜色color:标识了此顶点是尚未发现(白色),已经发现(灰色),还是已经完成探索(黑色)
还需用一个队列Queue来对已发现的顶点进行排列
决定下一个要探索的顶点(队首顶点)
BFS算法过程
从起始顶点s开始,作为刚发现的顶点,标注为灰色,距离为0,前驱为None,
加入队列,接下来是个循环迭代过程:
从队首取出一个顶点作为当前顶点;遍历当前顶点的邻接顶点,如果是尚未发现的白
色顶点,则将其颜色改为灰色(已发现),距离增加1,前驱顶点为当前顶点,加入到队列中
遍历完成后,将当前顶点设置为黑色(已探索过),循环回到步骤1的队首取当前顶点
'''
class Queue:
def __init__(self):
self.items = []
def isEmpty(self):
return self.items == []
def enqueue(self, items): # 往队列加入数据
self.items.insert(0, items)
def dequeue(self):
return self.items.pop()
def size(self):
return len(self.items)
def BFS(g, start): # g是图,start是起始的节点
start.setDistance(0) # 距离
start.setPred(None) # 前驱节点
vertQueue = Queue() # 队列
vertQueue.enqueue(start) # 把起始节点加入图中
while vertQueue.size() > 0: # 当搜索完所有节点时,队列会变成空的
currentVert = vertQueue.dequeue() # 取队首作为当前顶点
for nbr in currentVert.getConnections(): # 遍历临接顶点
if (nbr.getColor() == 'white'): # 当邻接顶点是灰色的时候
nbr.setColor('gray')
nbr.setDistance(currentVert.getDistance() + 1)
nbr.setPred(currentVert)
vertQueue.enqueue(nbr)
currentVert.setColor('balck')
def traverse(y):
x = y
while (x.getPred()):
print(x.getId())
x = x.getPred()
# print(x.getPred())
if __name__ == '__main__':
wordgraph = buildGraph('fourletterwords.txt')
BFS(wordgraph, wordgraph.getVertex('FOOL'))
traverse(wordgraph.getVertex('SAGE'))
print('FOOL')
看到结果输出的与上图不一致,但是经过的顶点的数量是相同的,都是最短路径,所以OK!!!
加餐第三题: 强连通分支(kosaraju算法)
关于强连通分支,前面有做过铺垫,找强连通分支有很多算法,这里将一个好理解的算法kosaraju算法,
- 算法流程: > 强连通分量分解可以通过两次简单的DFS实现。第一次DFS时,选取任意顶点作为起点,遍历所有尚未访问过的顶点,并在回溯前给顶点标号(post order,后序遍历)。对剩余的未访问过的顶点,不断重复上述过程。 > > 完成标号后,越接近图的尾部(搜索树的叶子),顶点的标号越小。第二次DFS时,先将所有边反向,然后以标号最大的顶点为起点进行DFS。这样DFS所遍历的顶点集合就构成了一个强连通分量。之后,只要还有尚未访问的顶点,就从中选取标号最大的顶点不断重复上述过程。
附上源视频链接
强连通分支(kosaraju算法)--陈斌老师(北大数据结构)
但是视频中可没有代码喔!!
那pd的nb之处还是展现出来了喔!!
话不多说,上代码!!!
# %%通用的深度优先搜索(kosaraju算法)
import sys
class Vertex:
def __init__(self, key):
self.id = key
self.connectedTo = {}
self.color = 'white'
self.dist = sys.maxsize # 无穷大
self.pred = None
self.disc = 0 # 发现时间
self.fin = 0 # 结束时间
def addNeighbor(self, nbr, weight=0): # 增加相邻边,
self.connectedTo[nbr] = weight
def __str__(self): # 显示设置
return str(self.id) + 'connectTo:' + \
str([x.id for x in self.connectedTo])
def getConnections(self): # 获得相邻节点
return self.connectedTo.keys()
def getId(self): # 获得节点名称
return self.id
def getWeight(self, nbr): # 获得相邻边数据
return self.connectedTo[nbr]
def setColor(self, color):
self.color = color
def getColor(self):
return self.color
def setPred(self, p):
self.pred = p
def getPred(self): # 这个前驱节点主要用于追溯,是记录离起始节点最短路径上
return self.pred # 该节点的前一个节点是谁
def setDistance(self, d):
self.dist = d
def getDistance(self):
return self.dist
def setDiscovery(self, dtime):
self.disc = dtime
def setFinish(self, ftime):
self.fin = ftime
def getFinish(self):
return self.fin
def getDiscovery(self): # 设置发现时间
return self.disc
class DFSGraph:
def __init__(self):
self.vertList = {} # 这个虽然叫list但是实质上是字典
self.numVertices = 0
self.time = 0 # DFS图新增time 用于记录执行步骤
def addVertex(self, key): # 增加节点
self.numVertices = self.numVertices + 1
newVertex = Vertex(key) # 创建新节点
self.vertList[key] = newVertex
return newVertex
def getVertex(self, key): # 通过key获取节点信息
if key in self.vertList:
return self.vertList[key]
else:
return None
def __contains__(self, n): # 判断节点在不在图中
return n in self.vertList
def addEdge(self, from_key, to_key, cost=1): # 新增边
if from_key not in self.vertList: # 不再图中的顶点先添加
self.addVertex(from_key)
if to_key not in self.vertList:
self.addVertex(to_key)
# 调用起始顶点的方法添加邻边
self.vertList[from_key].addNeighbor(self.vertList[to_key], cost)
def getVertices(self): # 获取所有顶点的名称
return self.vertList.keys()
def __iter__(self): # 迭代取出
return iter(self.vertList.values())
def dfs(self):
for v in self:
v.setColor('white') # 先将所有节点设为白色
v.setPred(-1)
for v in self:
if v.getColor() == 'white':
self.dfsvisit(v) # 如果还有未包括的顶点,则建立森林
def dfsvisit(self, stratVertex):
stratVertex.setColor('gray')
self.time += 1 # 记录步数
stratVertex.setDiscovery(self.time)
for v in stratVertex.getConnections():
if v.getColor() == 'white':
v.setPred(stratVertex) # 把下一个节点的前驱节点设为当前节点
self.dfsvisit(v) # 递归调用自己
stratVertex.setColor('black') # 把当前节点设为黑色
self.time += 1 # 设为黑色表示往回走了,所以步数加一
stratVertex.setFinish(self.time)
def kosaraju(self): # kosaraju划分强连通分支
self.dfs() # 第一步调用DFS,得到节点的Finish_time
# 第二步将图转置
self.transposformed() # 将图转置
# 对转置的图调用DFS,但不能直接调用
num = self.numVertices
max_finish = 0
while num > 0:
for v in self:
# 得到最大的Finish_time
if v.getColor() == 'black' and v.fin >= max_finish:
max_finish = v.fin
for v in self:
# 按照Finish_time从大到小组成深度优先森林
if v.fin == max_finish:
self.kosaraju_dfsvisit(v)
print('其中一个强联通分支是:')
for v in self:
if v.getColor() == 'gray': # 将灰色的都返回
print(v.getId(), end=' ')
v.setColor('white') # 将颜色设为白色
num -= 1 # 记录还剩多少节点
max_finish = 0
def transposformed(self):
Edge_tuples = [] # 里面装 某节点-指向->相邻节点和相邻边
for v1 in self: # 把所有节点取出来
for v2 in self: # 两两交换边
if v2 in v1.getConnections():
Edge_tuples.append((v1, v2, v1.getWeight(v2)))
v1.connectedTo = {} # 把v1的全部变成空
for v3 in Edge_tuples:
current_Vertex = v3[1] # current_Vertex 是原本被指向的节点
current_Vertex.addNeighbor(v3[0], v3[2])
def kosaraju_dfsvisit(self, stratVertex):
# 写一个专门用于kosaraju逆序的dfs
stratVertex.setColor('gray') # 把color从黑色转为灰色
for v in stratVertex.getConnections():
if v.getColor() == 'black':
v.setPred(stratVertex) # 把下一个节点的前驱节点设为当前节点
self.kosaraju_dfsvisit(v) # 递归调用自己
if __name__ == '__main__':
g = DFSGraph()
g.addEdge('A', 'B')
g.addEdge('B', 'E')
g.addEdge('B', 'C')
g.addEdge('C', 'F')
g.addEdge('E', 'A')
g.addEdge('E', 'D')
g.addEdge('D', 'G')
g.addEdge('D', 'B')
g.addEdge('G', 'E')
g.addEdge('F', 'H')
g.addEdge('H', 'I')
g.addEdge('I', 'F')
g.kosaraju()
正确结果:如图
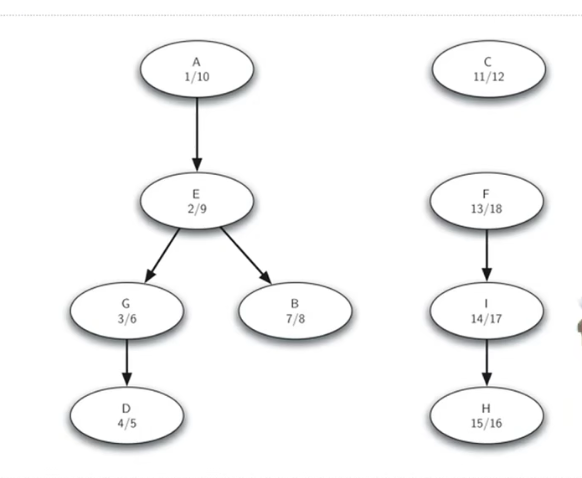
可以看到我们的结果与正确结果一致,OK!!!!
加餐第四题: 图的最短路径算法(Dijkstra算法)+ prim最小生成树
对于最短路径我们当然可以用DFS或者BFS来找到,但是Dijkstra算法也是一个很经典的算法
背景介绍在这里
话不多说,上代码!!!
# %%图的最短路径算法(Dijkstra算法)无法处理权值为负的情况
import sys
import numpy as np
class Binheap():
def __init__(self):
self.heaplist = [(0, 0)] # 专门用于Dijkstra算法,第一个是节点第二个是数值
# 因为要利用完全二叉树的性质,为了方便计算,把第0个位置设成0,不用他
'''
完全二叉树的特性 如果某个节点的下标为i
parent = i//2
left = 2*i
right = 2*i +1
'''
self.currentSize = 0
def perUp(self, i):
while i//2 > 0:
# 如果子节点比父节点要小,就交换他们的位置
if self.heaplist[i][1] < self.heaplist[i//2][1]:
self.heaplist[i], self.heaplist[i//2] =\
self.heaplist[i//2], self.heaplist[i]
i = i//2
def insert(self, k):
self.heaplist.append(k)
self.currentSize += 1
self.perUp(self.currentSize)
def delMin(self):
# 删掉最小的那个就是删掉了根节点,为了不破坏heaplist
# 需要把最后一个节点进行下沉,下沉路径的选择,选择子节点中小的那个进行交换
# 先把最后一个与第一个交换顺序
self.heaplist[1], self.heaplist[-1] =\
self.heaplist[-1], self.heaplist[1]
self.currentSize -= 1
self.perDown(1)
return self.heaplist.pop()
def minChild(self, i):
if i*2+1 > self.currentSize:
return 2*i
else:
if self.heaplist[2*i][1] < self.heaplist[2*i+1][1]:
return 2*i
else:
return 2*i+1
def perDown(self, i): # 下沉方法
while 2*i <= self.currentSize: # 只有子节点就比较
min_ind = self.minChild(i)
if self.heaplist[i][1] > self.heaplist[min_ind][1]:
# 如果当前节点比子节点中小的要大就交换
self.heaplist[i], self.heaplist[min_ind] =\
self.heaplist[min_ind], self.heaplist[i]
i = min_ind
else:
break # 如果当前节点是最小的就退出循环
def findMin(self):
return self.heaplist[1]
def isEmpty(self):
return self.heaplist == [(0, 0)]
def size(self):
return self.currentSize
def buildHeap(self, alist): # 这个alist里面装的元素是元组
# 将列表变为二叉堆
# 采用下沉法 算法复杂度O(N) 如果一个一个插入的话,算法复杂的将会是O(nlgn)
# 自下而上的下沉(先下沉最底层的父节点)
i = len(alist)//2
self.currentSize = len(alist)
self.heaplist = [(0, 0)] + alist
while i > 0:
self.perDown(i)
i -= 1
return self.heaplist
def __iter__(self):
for item in self.heaplist[1:]:
yield item
def __contains__(self, n): # 判断节点是否在优先队列内(专门为prim写的)
return n in [v[0] for v in self.heaplist]
class Vertex:
def __init__(self, key):
self.id = key
self.connectedTo = {}
self.color = 'white' # 为了解决词梯问题的
self.dist = sys.maxsize # 无穷大
self.pred = None
def addNeighbor(self, nbr, weight=0): # 增加相邻边,
self.connectedTo[nbr] = weight # 这个nbr是一个节点对象,不是名称
def __str__(self): # 显示设置
return str(self.id) + 'connectTo:' + \
str([x.id for x in self.connectedTo])
def getConnections(self): # 获得相邻节点
return self.connectedTo.keys()
def getId(self): # 获得节点名称
return self.id
def getWeight(self, nbr): # 获得相邻边数据
return self.connectedTo[nbr]
def setColor(self, color):
self.color = color
def getColor(self):
return self.color
def setPred(self, p):
self.pred = p
def getPred(self): # 这个前驱节点主要用于追溯,是记录离起始节点最短路径上
return self.pred # 该节点的前一个节点是谁
def setDistance(self, d):
self.dist = d
def getDistance(self):
return self.dist
class DIJKSTRAGraph:
def __init__(self):
self.vertList = {} # 这个虽然叫list但是实质上是字典
self.numVertices = 0
def addVertex(self, key): # 增加节点
self.numVertices = self.numVertices + 1
newVertex = Vertex(key) # 创建新节点
self.vertList[key] = newVertex
return newVertex
def getVertex(self, key): # 通过key获取节点信息
if key in self.vertList:
return self.vertList[key]
else:
return None
def __contains__(self, n): # 判断节点在不在图中
return n in self.vertList
def addEdge(self, from_key, to_key, cost=1): # 新增边
if from_key not in self.vertList: # 不再图中的顶点先添加
self.addVertex(from_key)
if to_key not in self.vertList:
self.addVertex(to_key)
# 调用起始顶点的方法添加邻边
self.vertList[from_key].addNeighbor(self.vertList[to_key], cost)
def getVertices(self): # 获取所有顶点的名称
return self.vertList.keys()
def __iter__(self): # 迭代取出
return iter(self.vertList.values())
def Dijkstra(self, startVertex): # 输入的stratVertex是节点的key
startVertex = self.vertList[startVertex]
startVertex.setDistance(0)
startVertex.setPred(None) # 将起始节点的前驱节点设置为None
pq = Binheap()
pq.buildHeap([(v, v.getDistance()) for v in self])
while not pq.isEmpty():
current_tuple = pq.delMin()
for nextVertex in current_tuple[0].getConnections():
newDistance = current_tuple[0].getDistance() +\
current_tuple[0].getWeight(nextVertex)
# 如果当下一节点的dist属性大于当前节点加上边权值,就更新权值
if newDistance < nextVertex.getDistance():
nextVertex.setDistance(newDistance)
# 把更新好的值重新建队
pq.buildHeap([(v[0], v[0].getDistance()) for v in pq])
if not pq.isEmpty():
# 把下一节点的前驱节点设置为当前节点
nextVertex_set_pred = pq.findMin()[0]
nextVertex_set_pred.setPred(current_tuple[0])
def minDistance(self, from_key, to_key):
self.Dijkstra(from_key)
to_key = self.getVertex(to_key)
min_distance = to_key.getDistance()
while to_key.getPred():
print(to_key.getId()+'<--', end='')
to_key = to_key.getPred()
print(from_key+' 最短距离为:', min_distance)
def matrix(self, mat): # 这里的mat用numpy传进来
key = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
for i in range(len(mat)): # 邻接矩阵行表示from_key
for j in range(len(mat)): # 列表示to_key
if i != j and mat[i, j] > 0:
self.addEdge(key[i], key[j], mat[i, j])
def prim(self, startVertex):
pq = Binheap()
for v in self:
v.setDistance(sys.maxsize)
v.setPred(None)
startVertex = self.vertList[startVertex]
startVertex.setDistance(0)
pq.buildHeap([(v, v.getDistance()) for v in self])
while not pq.isEmpty():
current_tuple = pq.delMin()
for nextVertex in current_tuple[0].getConnections():
# 注意这里是两顶点找最短边(因为是贪心算法)而不是找全局最短
newWeight = current_tuple[0].getWeight(nextVertex)
# 当这个节点在图中且新的权重比旧权重小,就更新权重,更新连接
if nextVertex in pq and newWeight < nextVertex.getDistance():
nextVertex.setDistance(newWeight)
nextVertex.setPred(current_tuple[0])
# 对优先队列从新排列
pq.buildHeap([(v[0], v[0].getDistance()) for v in pq])
for v in self:
if v.getPred():
print(f'节点{v.getId()}的前驱节点是{v.getPred().getId()}')
if __name__ == '__main__':
DijGraph = DIJKSTRAGraph()
inf = float('inf')
a = np.array([[0, 1, 12, inf, inf, inf],
[inf, 0, 9, 3, inf, inf],
[inf, inf, 0, inf, 5, inf],
[inf, inf, 4, 0, 13, 15],
[inf, inf, inf, inf, 0, 4],
[inf, inf, inf, inf, inf, 0]])
DijGraph.matrix(a)
DijGraph.minDistance('A', 'F')
DijGraph.prim('A') # 输出最小生成树
写在最后
好啦,我这个阶段的图论笔记就到此为止啦,笔记里面当然有很多写的不好的地方,还有一些算法是没有实现的,比如那个欧拉道路的算法,感兴趣的同学写好了可以PULL到我的Github仓库,
也可以发邮件给我 我的个人邮箱是 395286447@qq.com
然后文章中出现的所有代码都在我的Github仓库里,潘登同学的Github仓库
