
# 概率图模型--贝叶斯网络 -- 潘登同学的Machine Learning笔记 @
概率图模型
什么是概率图
概率图只是一个框架, 是一种方法论, 跟计算机中的
万物皆可动规的思路一样;
概率图是概率论与图论的结合产物, 为统计推理和学习提供了一个统一灵活的框架;
概率图模型提供了一个描述框架, 使我们能够将不同领域的知识抽象为概率模型, 将各种应用中的问题都归结为计算概率模型里某些变量的概率分布, 从而将知识表示和推理分开来
其实图论也不是必要的, 只是借用了图的一些特点来描述概率模型, 如果你对图论感兴趣, 那么你可以去康康潘登同学的图论笔记
概率图模型的三要素--表示、推理、学习
概率图模型的表示
图中节点: 表示变量
图中边: 表示局部变量间的概率依赖关系
概率图模型的表示刻画了模型的随机变量在变量层面的依赖关系, 反应出问题的概率结构, 为推理算法提供了数据结构, 概率图模型的表示方法主要有贝叶斯网络, 马尔科夫随机场, 因子图等;
- 贝叶斯网络

- 马尔科夫随机场

- 因子图

概率图模型表示主要研究的问题是, 为什么联合概率分布可以表示为
局部势函数的联乘积形式, 如何在图模型建模中引入先验知识;
概率图模型的推理
求解边缘概率 $$ p(\bf{x_a}) = \sum_{\bf{x \diagdown x_{\alpha}}} $$
求最大后验概率状态 $$ X^{*} = \argmax_{\bf{x}\in \chi} p(\bf{x}) $$
求归一化因子 $$ Z = \sum_{\bf{x}} \prod_{c} \phi_c(\bf{x}_c) $$
概率图模型的学习
参数学习: 已知图模型的结构, 学习模型的参数;
结构学习: 从数据中推断变量之间的依赖关系;
三者的联系
flowchart TB
概率图模型的表示 --> 概率图模型的推理
概率图模型的学习 --> 概率图模型的表示
贝叶斯网络
但在此之前要引入一些预备知识;
朴素贝叶斯
贝叶斯公式 $$ P(A|B) = \frac{P(B|A)P(A)}{P(B)} $$
机器学习下的贝叶斯公式
把B理解为具有某种特征X, 把A理解为具有某种标签Y;改写贝叶斯: $$ P(Y|X) = \frac{P(X|Y)P(Y)}{P(X)} $$
深刻理解 上面的公式左边是要求解的先验概率!!! 右边是从历史数据中获取的, 历史数据即知道X和Y也能计算P(X|Y), 而我们要求的是, 在已知X的条件下Y出现的概率(也就是由因索果);
注意 上面公式成立的条件: 特征间相互独立
其实跟我们的PCA的结果一样, 其实也跟多元线性回归的假设一样(多元线性回归不允许出现多重共线性, 因为系数不能解释, 而机器学习没有这个假设, 但是存在相关关系会让机器学习的数据质量下降, 这里不做详细讨论)
- 由特征独立再改写贝叶斯
则有: $$ P(X) = P(x_1)P(x_2)\cdots P(x_n) (x_i\in X(i=1,2,\ldots, n) $$
所以: $$ P(X|Y) = P(x_1|Y)P(x_2|Y)\cdots P(x_n|Y) $$
贝叶斯公式: $$ P(Y|X) = \frac{\prod_{i=1}^{n}P(x_i|Y)P(Y)}{\prod_{i=1}^{n}P(x_i)} $$
上式也被称为朴素贝叶斯
贝叶斯网络
有向无环图模型, 是一种模拟人类推理过程中因果关系的不确定处理模型, 其网络拓扑构造是一个有向无环图;
本质还是贝叶斯那套
flowchart LR
id1["P(因|果)"] --历史数据--> id2["P(果|因)"]
- 示意图
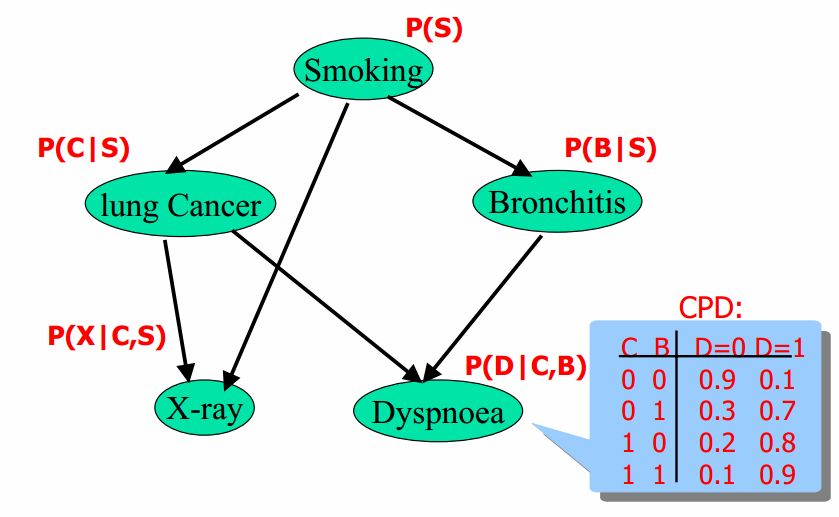
贝叶斯网络有向无环图中的节点表示随机变量${x_1, x_1, \ldots, x_n}$(可以是可观测到的变量、隐变量、未知参数等); 认为有因果关系(非条件独立)就可以相连;
如上图中的Smoking会导致lung Cancer, 就可以相连, 边权值就是条件概率;
提到了非条件独立, 我们先说条件独立
条件独立
上图可以表示为 $$ P(S,C,X,B,D) = P(S)P(C|S)P(B|S)P(X|C,S)P(D|C,B) $$
问题联合概率的乘积为什么能表示局部条件概率表的乘积? > 因为条件独立;
3个重要的链接模型
flowchart LR
id1((a)) --> id2((c))--> id3((b))
head-to-tail(最重要)
- c未知 $$ P(a,b,c) = p(a)p(c|a)p(b|c) \nRightarrow p(a,b) = p(a)p(b) $$
所以a,b不独立;
- c已知 $$ \begin{aligned} P(a,b|c) &= \frac{P(a,b,c)}{P(c)} \ &= \frac{P(a)P(c|a)P(b|c)}{P(c)} \ &= \frac{P(ac)P(b|c)}{P(c)} \ &= P(a|c)P(b|c) \ \end{aligned} $$ 所以a,b(条件)独立;
flowchart TB
id1((c)) --> id2((a)) & id3((b))
tail-to-tail
- c未知 $$ P(a,b,c) = p(a)p(c|a)p(b|c) \nRightarrow p(a,b) = p(a)p(b) $$
所以a,b不独立;
- c已知 $$ \begin{cases} P(a,b|c) = \frac{P(a,b,c)}{P(c)} \ P(a,b,c) = P(c)P(a|c)P(b|c) \ \end{cases} \Rightarrow P(a|c)P(b|c) $$
所以a,b(条件)独立;
flowchart TB
id2((a)) & id3((b))--> id1((c))
head-to-head
- 无论c知不知道 $$ P(a,b,c) = P(a)P(b)P(c|a,b) $$
所以a,b独立;
深刻理解独立与条件独立
独立与条件独立没啥关系, 只是字面上很相近;
独立与条件独立不能互推, 看如下反例:第一个反例是独立推不出条件独立:有两枚正反概率均为 50% 的硬币,设事件 A 为第一枚硬币为正面,事件 B 为第二枚硬币为正面,事件 C 为两枚硬币同面。A 和 B 显然独立,但如果 C 已经发生,即已知两枚硬币同面,那么 A 和 B 就不(条件)独立了。
第二个反例是条件独立推不出独立:有一枚硬币正面的概率为 99%,另一枚反面的概率为 99%,随机拿出一枚投掷两次,事件 A 为第一次为正面,事件 B 为第二次为正面,事件 C 为拿出的是第一枚硬币。可以算出来 P(B) = 0.5 但 P(B|A) = 0.9802,说明 A 和 B 不独立,但如果 C 已经发生,即已知了拿出的是第一枚硬币,那么 A 和 B 就(条件)独立了。
回到 联合概率的乘积表示为局部条件概率表的乘积
$$ P(S,C,X,B,D) = P(S)P(C|S)P(B|S)P(X|C,S)P(D|C,B) $$
- 观察这一条
flowchart LR
id2((Somking)) --> id3((Bronchitis))--> id1((Dyspnoea))
当已知Bronchitis时, Somking就与Dyspnoea相互独立了, 所以他俩就没啥关系, Dyspnoea就只取决于Bronchitis了, 所以就可以将$P(Dyspnoea|Bronchitis, Somking)写成P(Dyspnoea|Bronchitis)$
看到了吧, 概率图的优势就来了, 就把原本两组的参数, 化简为一组了;
详解边权值
上面说的参数就是边权值, 边权值才是我们模型要训练的模型!!!!
上图蓝色框的就是参数, 如第一个参数0.9表示: 已知C=0,B=0时, D=0的概率;
如果不用图结构来表示的话, 就还需要一组'S'的参数(因为S也间接指向D), 那么左边的要 $2\times 2\times 2=8$, 那么参数的个数就要$8\times 2=16$个;
所以图模型的条件独立给我们极大的减少了模型的参数;
再说说朴素贝叶斯为啥叫朴素?
因为朴素贝叶斯假设所有自变量都是独立的, 如果表示在图中就是没有边的图, 全是散点, 很简单, 很朴素,所以也叫朴素贝叶斯;
贝叶斯网络就是这样了, 继续下一章吧!pd的Machine Learning
