
Word2Vec进阶 - ELMO -- 潘登同学的NLP笔记

ELMO
ELMo出自Allen研究所在NAACL2018会议上发表的一篇论文《Deep contextualized word representations》,从论文名称看,应该是提出了一个新的词表征的方法。据他们自己的介绍:ELMo是一个深度带上下文的词表征模型,能同时建模
- 单词使用的复杂特征(例如,语法和语义);
- 这些特征在上下文中会有何变化(如歧义等)。
这些词向量从深度双向语言模型(BiLSTM)的隐层状态中衍生出来,BiLSTM是在大规模的语料上面Pretrain的。它们可以灵活轻松地加入到现有的模型中,并且能在很多NLP任务中显著提升现有的表现,比如问答、文本蕴含和情感分析等。
原理
之前我们一般比较常用的词嵌入的方法是诸如SkipGram和GloVe这种,但这些词嵌入的训练方式一般都是上下文(相对长的上下文)无关的,并且对于同一个词,不管它处于什么样的语境,它的词向量都是一样的,这样对于那些有歧义的词非常不友好。因此,论文就考虑到了要根据输入的句子作为上下文,来具体计算每个词的表征,提出了ELMo(Embeddings from Language Model)。它的基本思想,用大白话来说就是,还是用训练语言模型的套路,然后把语言模型中间隐含层的输出提取出来,作为这个词在当前上下文情境下的表征,简单但很有用!
整体架构

- 首先经过一个字符编码层,因为ELMo实际上是基于char的,所以它会先对每个单词中的所有char进行编码,从而得到这个单词的表示,经过Char Encoder layer层出来的维度是$(B,W,D)$
- 随后该句子表示会经过BiLMs,即双向语言模型的建模,内部其实是分开训练了两个正向和反向的语言模型,而后将其表征进行拼接,最终得到的输出维度为$(L + 1, B, W, 2D)$,L+1实际上是将L个BiLSTM的输出结果,加上了最初的embedding层,得到的$L+1$维的输出
- Scalar Mixer:紧接着,得到了biLMs各个层的表征之后,会经过一个混合层,它会将前面这些层的表示进行加权求和,这一层主要是训练权重值
Char Encoder Layer

- 输入的句子会被reshape成B W ∗ C BW * CBW∗C,因其是针对所有的char进行处理
- Char Embedding: 针对每个char进行编码,实际上所有char的词表大概是262,其中0-255是char的unicode编码,256-261这6个分别是
<bow>(单词的开始)、<eow>(单词的结束)、<bos>(句子的开始)、<eos>(句子的结束)、<pow>(单词补齐符)和<pos>(句子补齐符),所以Char Embedding中的参数是$262∗d$,$d$ 表示的是字符的embedding维度,与最终的输出D不同,而 D 表示的是单词的embedding维度 - Multi-Scale卷积层:这里用的是不同scale的卷积层,卷积之间的不同在于其
kernel_size和channel_size的大小不同,用于捕捉不同n-grams之间的信息;这里的卷积都是1维卷积,即只在序列长度上做卷积,根据不同的channel_size的大小,有不同大小的输出$d_1,d_2,\ldots,d_m$ - Concat层: 拼接并且reshape成$(B,W,d_1+d_2+\ldots+d_m)$
- Highway层: 借鉴了残差的思想,做的全连接与残差加和形式
- Linear层: 用全连接将$d_1+d_2+\ldots+d_m$转换为D
BiLSTM

ELMO词向量
经过了BiLSTM之后,得到的表证维度为$(L + 1, B, W, 2D)$,接下来就是生成最终的ELMO向量了
再次强调,ELMO只是一个预训练Embedding层的模型,只需要语料库,不需要标签,目的也只是更好的描述词与词之间的关系
Scalar Mixer的作用主要是对$L+1$个张量,进行加权求和操作,每一个权重$\alpha$都是要学习的值,求和完后前面还有一个缩放系数$\gamma$,针对不同任务会有不同的值,也是要求学习的
同时论文里面还提到,每一层输出的分布之间可能会有较大差别,所以有时也会在线性融合之前,为每层的输出做一个Layer Normalization,这与Transformer里面一致。
经过Scalar Mixer之后的向量维度为$B ∗ W ∗ 2D$,即为生成的ELMo词向量,可以用于后续的任务
实验结果
这里主要列举一些在实际下游任务上结合ELMo的表现,分别是SQuAD(问答任务)、SNLI(文本蕴含)、SRL(语义角色标注)、Coref(共指消解)、NER(命名实体识别)以及SST-5(情感分析任务),其结果如下:
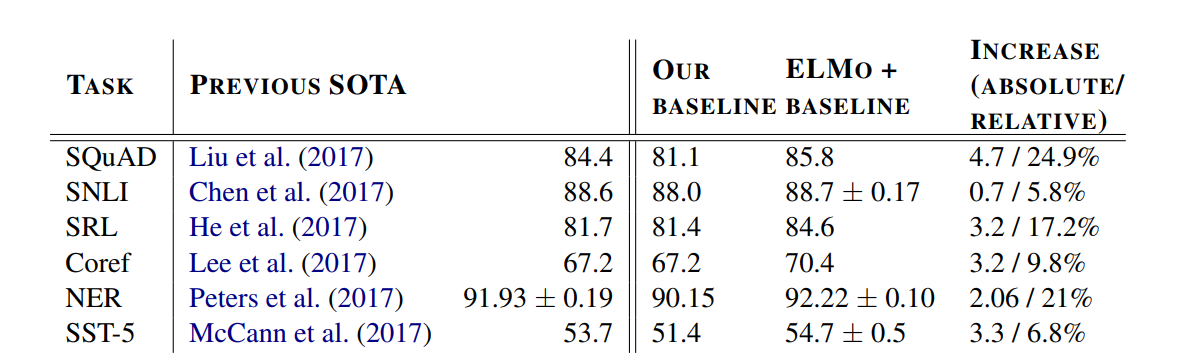
可见,基本都是在一个较低的baseline的情况下,用了ELMo后,达到了超越之前SoTA的效果!
总结
ELMo具有如下的优良特性:
- 上下文相关:每个单词的表示取决于使用它的整个上下文。
- 深度:单词表示组合了深度预训练神经网络的所有层。
- 基于字符:ELMo表示纯粹基于字符,然后经过CharCNN之后再作为词的表示,输入的词表很小。
