
YOLO-v1论文详解 -- 潘登同学的目标检测笔记
与Faster R-CNN最大不同
- 所有loss都是回归问题
- 端到端网络,网络结构简单
- 快!!!
You Only Look Once
YOLO就是You Only Look Once的缩写,一看就很快对吧...
算法流程
- Resize image: 将输入图片resize成448*448(因为前20层卷积是用imageNet大赛数据集训练(大赛的数据是224*224))
- Run ConvNet: 使用CNN提特征,FC层做回归
- Non-maximal suppression suppression: 对最终的结果进行筛选(预测时)
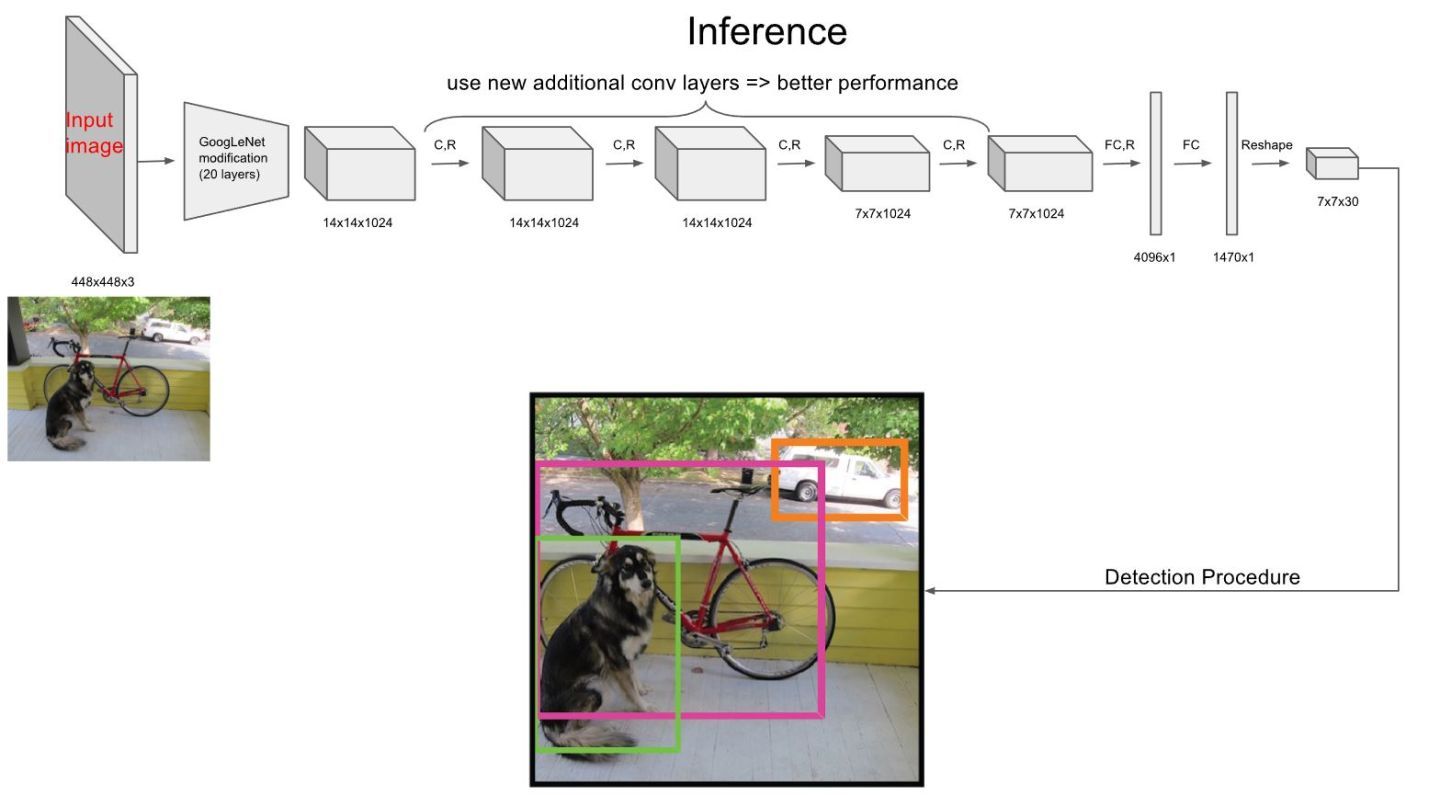
网络结构部分

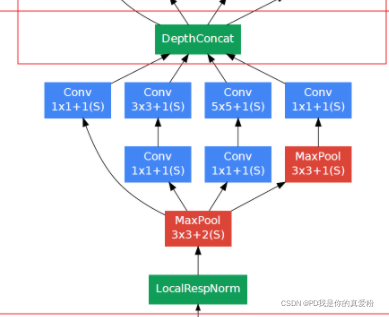
网络结构借鉴了GoogleNet(也就是之前说的Inception)中的NIN部分,他这里直说到了1*1卷积接3*3卷积, 但是如果只借鉴这一部分,那跟普通的卷积层区别其实不是很大(我猜可能是因为之前的普通卷积一般都是3*3接3*3或者5*5接5*5,一般都是保持不变或者卷积核越来越小),但是这里的1*1卷积接3*3卷积与以往的不同, 但是网络结构中并没有真正用NIN...
- 这是Inception中的NIN结构
- 论文中的网络结构

Anchor部分
- 与Faster R-CNN一样,YOLO-v1也有Anchor,Anchor的作用是预测该区域属于哪一类;而与Faster R-CNN不同的是,YOLO-v1的anchor不需要先预测是前景还是背景(也就是没有预测是不是obj那个步骤);
- 与Faster R-CNN一样,YOLO-v1也有类似的bounding boxes(YOLO有两个),与Faster R-CNN不同的是,Faster R-CNN的9个bounding boxes是事先定义的,最后通过线性变换进行缩放平移;而YOLO-v1则是根据GT来学习的
输出结果

最终卷积网络出来的结果是S*S(S=7)的feature map,一个像素点就对应着原图的64*64的范围,对于这个范围每个bounding boxes(B=2),需要给出他属于哪一类(总共有C=20类),一个bounding boxes有四个位置参数,那么总共就有$S \cdot S \cdot (B \cdot 4 + C)$
但是论文中却是$S \cdot S \cdot (B \cdot 5 + C)$那多出来的这一个B又是啥呢?
前面Anchor部分: YOLO-v1的anchor不需要先预测是前景还是背景(也就是没有预测是不是obj那个步骤) 那在训练的时候总会有他不是obj的负例样本啊,那很明显他不属于某一类,坐标也无从谈起啊,那咋整涅?
于是作者采用了一个confidence的理念 $$ confidence = Pr(object) * IOU_{pred}{truth} $$
要注意的是,这个confidence在正向传播的时候不是先预测一个$Pr(object)$再与GT的IOU相乘得到的,这个confidence就是一个隐藏层,是我们想让网络学到的,按照直觉confidence肯定是越大越好; 但是在构造训练集的confidence的label时候,就是按照这个公式构造的,也就是对于7*7*2个bounding boxes,那么只有GT就是1; 或者这样理解,confidence其实就是我们要求网络计算的一个指示变量,当这个指示变量接近1的时候,就认为这个框框住的是某一个物体, 当confidence接近0的时候,就认为这个框框住的不是物体;在这种情况下,负例样本也可以让网络学到东西,学到的东西就是这个指示变量;
Loss函数
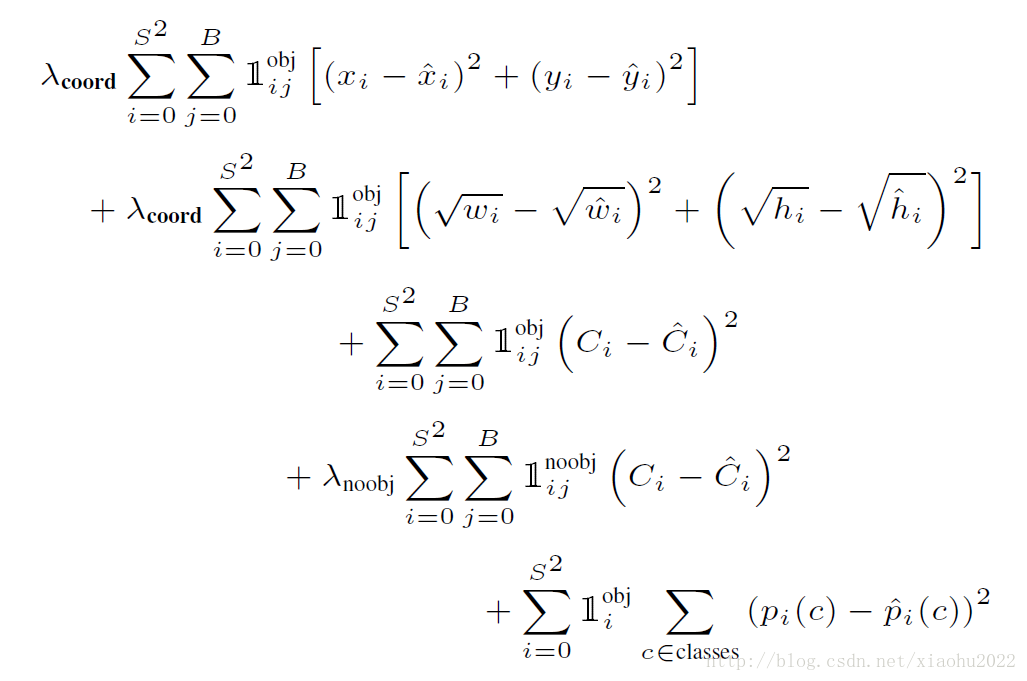
Loss主要分为三部分
- 包含obj的框 的 位置loss(x,y,w,h)
- 所有框的confidence loss
- 包含obj框 的 分类loss
位置Loss
这里的(w,y,w,h)都是$[0,1]$之间的值,因为每个(w,y,w,h)都是来自于某一个特定的Anchor,以该Anchor的左上角为原点,右下角为(1,1)的一个坐标系来构建的(w,y,w,h); 那为啥要这样做呢,直接用绝对坐标不是更省事吗,gt数据集还不用处理了...
以我的观点: 因为YOLO中所有都是回归问题,回归问题的解空间是$[-\infty,\infty]$,一旦采用了绝对坐标,那么就很难收敛,因为与坐标信息一起出去的还有分类信息,只在一个隐藏层特别是一个FC中很难做到一部分大一部分小; 那为什么是[0,1]而不是其他的[4,5]之类的呢? 因为分类的probability是[0,1],所以也用了[0,1]就保证了是在同一个维度上;所以一切东西弄到一个范式里面是有好处的....
这里的w,h的loss上面带了个根号,是为了大幅度地调小框,小幅度地调大框。 w越大,相对应的loss,应该更小,或者说小框的调整幅度在中心点差距相同时,调的幅度更大;如下图所示,相同的中心点差距,大框的IOU更大,而小框的IOU为0

confidence Loss
理解这个confidence Loss的关键是要将Loss解耦,要知道Loss的哪一部分是网络给出的,那一部分是label的值,那一部分是即考虑Label又考虑网络的; 这一段论文中没有详细说,是看源码才能知道的...
$S,B$对应feature map的size、bbox数量,带有帽子的$\hat{?}$的都是网络中得到的,$(x,y,w,h)$以及class都是数据给出的,这没啥问题; 重点是这个$C$,他是考虑了$(\hat{x},\hat{y},\hat{w},\hat{h})$计算出预测框与gt的IOU,再乘上label中这个Anchor是否对应了obj而得到的; 所以这个$C$是一个耦合的变量;
以下是我上github上找的一个实现,写的不简洁,但是注释很清楚,不是矩阵运算,更容易看懂

分类Loss
这里的分类Loss也是用回归的方法做的,loss函数就是MSE,与一般的交叉熵比起来肯定没那么优秀啦..
注意 还有一个值得注意的,就是那些$1^{obj}_{i,j}$也是label值,网络中没有这一项输出,只能是label; 还有一个同样重要的,Faster R-CNN是先NMS筛框,而YOLO-v1则是先算loss,最终预测的时候才用NMS筛框..
Loss前面的系数
最后就是Loss前面的系数了,这其实就是炼丹了,也没啥好说的,讲一下思想就行
因为都是MSE loss,所以得到的loss其实应该是差不多的,那么想要更重视那些,更不重视那些,就可以通过系数来设置
- 更重视坐标预测,因为框对了才能预测对, 在论文中将前面的系数取了5
- 对没有obj的confidence loss因为他是负例,重视程度比较低(因为只是调confidence loss),论文中取了0.5
- 对于分类loss取了1
Limitation
- 因为YOLO中每个cell只预测两个bbox和一个类别,这就限制了能预测重叠或邻近物体的数量,比如说两个物体的中心点都落在这个cell中,但是这个cell只能预测一个类别
- 此外,不像Faster R-CNN一样预测offset,YOLO是直接预测bbox的位置的,这就增加了训练的难度。
- YOLO是根据训练数据来预测bbox的,但是当测试数据中的物体出现了训练数据中的物体没有的长宽比时,YOLO的泛化能力低
- 同时经过多次下采样,使得最终得到的feature的分辨率比较低,就是得到coarse feature,这可能会影响到物体的定位。 是当测试数据中的物体出现了训练数据中的物体没有的长宽比时,YOLO的泛化能力低
- 同时经过多次下采样,使得最终得到的feature的分辨率比较低,就是得到coarse feature,这可能会影响到物体的定位。
- 损失函数的设计存在缺陷,使得物体的定位误差有点儿大,尤其在不同尺寸大小的物体的处理上还有待加强。(那个开根号也不过是一种工程做法,开根号的做法不一定是最优的)
不过整体看下来,YOLO还是很简洁,很简单粗暴的,这样的网络改进空间大,而且代码也好写...
